最近在看SLA,看到里面一个词叫混沌工程,故整理一下。
定义:混沌工程是一门对系统进行实验的学科,旨在了解系统对应生产环境的各种混乱状况的能力,建立对系统的信心。所有系统的用户都希望系统具备可靠性,但影响可靠性的因素有很多。混沌工程师能找到证据,指明那些异常但不可回避的状况下系统的应变情况。
简单来说:混沌工程是在分布式系统上进行实验的学科,目的是建立对该系统能够承受生产环境的动荡的信心。
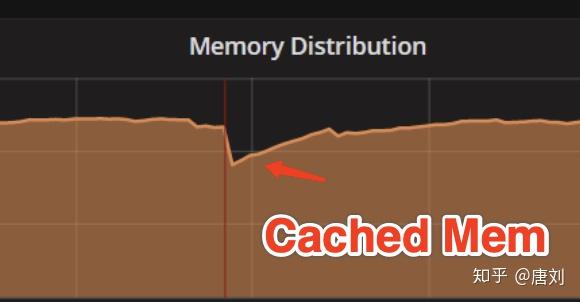
我们的用户将 TiDB 运行在国内某云厂商的机器上面,然后跟我们反映,读延迟会不定期的增长,我们看了看监控,发现唯一的异常指标就是 Cached 的 memory 那段时间会突然下降。当时真的就懵逼了,完全不知道是为啥,最终发现,云厂商的运维监控脚本里面有个 bug,会不定期的将磁盘热拔插,并且将现有的 page cache 刷到磁盘,所以那段时间 TiDB 的 read 操作很多是从磁盘重新读取数据的。
可以看到,分布式系统真的是一个非常复杂的系统,故障无处不在,那么我们如何在这么复杂的分布式系统的世界里面生存下去呢?现在,一个很好的答案就是 – Chaos Engineering,中文里面叫做混沌工程。
Netflix工程师创建了Chaos Monkey,使用该工具可以在整个系统中在随机位置引发故障。正如GitHub上的工具维护者所说,“Chaos Monkey会随机终止在生产环境中运行的虚拟机实例和容器。”通过Chaos Monkey,工程师可以快速了解他们正在构建的服务是否健壮,是否可以弹性扩容,是否可以处理计划外的故障。
2012年,Netflix开源了Chaos Monkey。今天,许多公司(包括谷歌,亚马逊,IBM,耐克等),都采用某种形式的混沌工程来提高现代架构的可靠性。 Netflix甚至将其混沌工程工具集扩展到包括整个“Simian Army(中文可以译为猿军)”,用它攻击自己的系统。
混沌工程
相比于我们成天担惊受怕系统会出现什么样的问题,还不如提前就模拟线上环境可能出现的各种情况,来看我们的系统是否能做到容错,仍然能继续对外提供服务。当然,我们并不是简单的就在线上环境上面,把机器给断电,或者把网线给拔掉,在混沌工程领域,有一套指导原则,以及标准的实验步骤,具体的可以参考 PRINCIPLES OF CHAOS ENGINEERING 。
简单来说,要做一次混沌实验,我们只需要做到如下的 4 个步骤:
- 定义系统的稳态,这个稳态就是系统在正常运行的时候一些指标,譬如当前请求的 QPS,latency 这些。
- 将系统分为实验组以及对照组,做出一个假设,譬如我在实验组引入一个故障,这个稳态仍然能在实验组保持。
- 执行试验,给实验组引入现实世界中的故障,譬如拔掉网卡。
- 验证第 2 步的假设是否成立,如果实验组的稳态跟对照组不一样了,证明我们的系统在第 3 步的故障中不能很好的容错,所以我们需要改进。
可以看到,上面的步骤非常的简单,但要在实际从很好的做混沌试验,还是有一些困难的,主要在以下几点:
- 自动化,我们需要有一套自动化的系统帮我们进行故障注入,进行假设对比等。
- 尽可能多的引入不同故障。现实环境中可能会出现非常多的故障,仅仅不是拔网线这么简单,所以引入的故障越多越好。
- 业务方无感知。如果我们每次做混沌试验,都要业务系统去配合,譬如在业务里面写一些混沌相关的代码,让混沌试验调用,或者更改系统的部署逻辑,跟混沌试验配合,这种的就属于紧耦合的。
你好,ChaosMesh!!!
所以,为了让大家更好的做混沌试验,我们开发了 ChaosMesh,ChaosMesh 是一套基于 Kubernetes 的云原生混沌工程平台。ChaosMesh 的架构如下:
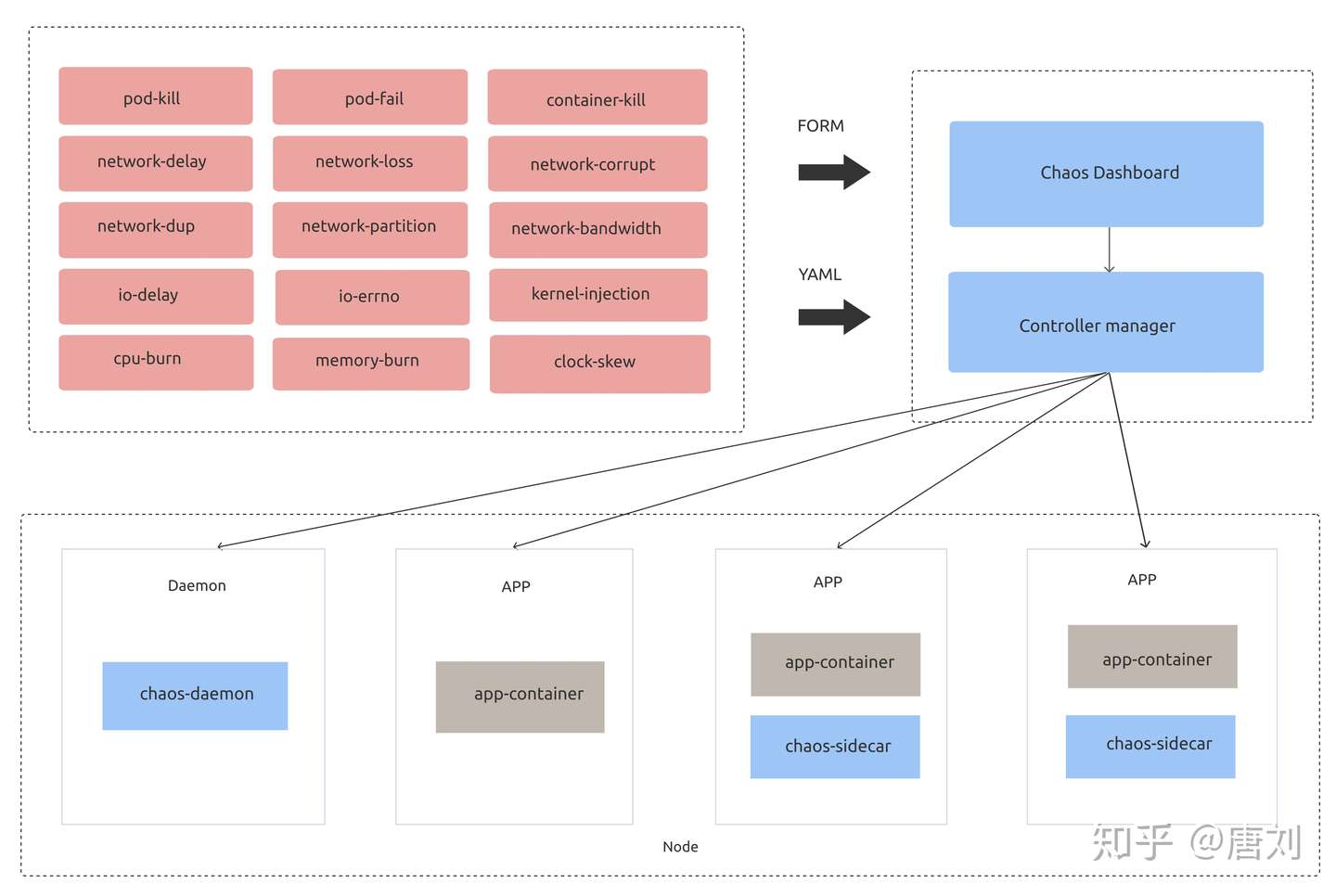
相比于其他混沌平台,ChaosMesh 有如下优势:
- 基于 K8s,只要你的系统能跑在 K8s 上面,那么就可以无缝的集成 ChaosMesh,而且不用修改任何业务代码,真正是被测系统无感知。
- 多种多样的故障注入。ChaosMesh 能全方位的帮你对网络,磁盘,文件系统,操作系统等进行故障注入。我们后面也会提供对 K8s,或者云服务自身进行 chaos 的能力。
- 易于使用,你无需关注 ChaosMesh 的底层实现细节,只需用 YAML 配置好混沌试验,就可以实施,后面所有的实验是全自动化的。我们也提供了 Dashboard 能让你在网页上就轻松的进行试验。
- 可观测性,ChaosMesh 的 Dashboard 能很方便的让你观测系统,知道什么时候进行了什么试验,知道你自己的系统当前的运行情况,当然,这里需要一点配置,你需要告诉 ChaosMesh 如何去获取你系统的稳态指标,譬如你的系统使用 Prometheus,那么就可以告诉 ChaosMesh 如何去 Prometheus 查询相关的监控指标。
- 强大的开源社区支持,ChaosMesh 的社区成长的非常迅速,我们非常高兴的看到大部分的功能已经由社区支持,并且也有很多用户。你无需担心遇到问题不知道如何解决,当然,你可能要担心下 ChaosMesh 做实验的时候把你的数据给完全干掉,所以做实验的时候一定要控制好实验半径,这个也是混沌工程的一条原则。
来一次 Chaos 实验?
在我们开始一次 Chaos 实验之前,你首先需要满足两个条件:
- 你自己的业务是跑在 K8s 上面的
- 在 K8s 上面安装了 ChaosMesh
另外,在开始实验之前,这里我还是要强调一下 Chaos 实验的一些注意事项,可能你觉得我这个大叔很啰嗦,但小心驶得万年船,因为稍微一不注意,你可能就丢了数据了。
- 如果你刚准备将你的系统应用 ChaosMesh,一定要保证首先在测试环境中使用。你的系统应该还非常的脆弱,如果在线上进行试验,会非常的危险。
- 在生产系统中,一定要控制好试验的爆炸半径,控制好影响范围,譬如我们可以先对某一个街道的用户进行干扰,然后在扩大到某一个区域,或者某一个城市,如果我们一开始的影响半径就很大,一个稍微不留意,你的 boss 就可能让你第二天滚蛋了。
- 做混沌实验一定不是随机的瞎做实验,我们是带有目的的,是需要规划好的,与其漫无目的的对系统随机进行故障注入,我们还不如先问自己一个问题『为了对系统在混乱状况下的表现更有信心,在哪里做混沌实验最有价值?』也就是我们要熟悉了解我们的系统,做高杠杆价值的混沌实验。
好了,现在你已经完全准备好了,现在就可以踏上混沌之旅了,因为 ChaosMesh 的使用是如此简单,你只需要参考 用户指南 就能上手使用,所以我就不过多介绍了,如果你仍然遇到了问题,欢迎给 ChaosMesh 提 issue,相信我,ChaosMesh 社区会很热情的帮你解决问题的。
总结
随着 ServiceMesh,Serverless 等理念的兴起,我们的系统真的趋向于越来越分布式,这样虽然简化了我们单个模块的实现,但整体来看,也可能会导致我们的系统因为过于分布式而变得复杂,那么如何在这种复杂的环境下仍然让我们有信心能保证系统能正常稳定运行,混沌工程可以算是一个很不错的选择。
现在市面上面,支持混沌工程的平台已经有很多了,但我这里仍然推荐 ChaosMesh,毕竟使用它能让你极大提升你对系统的信心。
该咋做混沌工程?
在讨论咋做混沌工程之前,让我们先回答下面5个问题。
什么是混沌工程?
先说一个能说出点名堂的我个人对混沌工程的理解,**混沌工程,是Netflix公司当面对具有不可预知的“暗债”的复杂系统时,在“目标一致,关系宽松”的企业文化下,“逼上梁山”的结果**。
什么是“暗债”?这个词来源于2017年发表的一篇名为[STELLA](https://snafucatchers.github.io/)的报告。这份报告由一群韧性工程专家在聚会后所撰写。就在他们聚会的那几天,这群专家赶上了一场极具破坏性的暴风雪。而那场暴风雪的名字,就是 STELLA。
**暗债**,指当复杂系统内部子系统间相互作用时,所**必然存在**的**不可预知**的漏洞,最终会由此引发系统的意外故障。
再说说上面那个“除了‘实验’貌似啥也没说”的定义。
2015年,Netflix将混沌工程正规化,主持起草了[混沌工程原则](https://principlesofchaos.org/?lang=ENcontent),并给混沌工程下了定义。
混沌工程是在分布式系统上进行实验的学科,目的是建立对该系统能够承受生产环境的动荡的信心。
“貌似啥也没说”的背后,其实这个定义是大有深意的。
- 分布式系统就是一种复杂系统,其活动规律是**不可预知和非线性的**。详情参见我之前撰写的[“不可能构建第二个云环境去做测试”](“不可能构建第二个云环境去做测试”——为复杂混沌的微服务生产环境设计韧性系统 v0.11)和[“混沌工程与系统稳定性设计模式”](https://myslide.cn/slides/22341)
- 生产环境的动荡,来源于复杂系统内部**所固有的“暗债”**。见与不见,暗债就在那里,不增不减
- 具有“可证伪性”的科学实验,只关注所定义的稳态是否被证伪,而对于**具体采取哪种方法保持稳态,不做要求**,悉听尊便,这就孕育了混沌猴
- 要建立对系统能够承受生产环境的动荡的信心,需要**针对生产环境“丰富多彩”的暗债,设计同样“丰富多彩”的防范手段**。依据是控制论学者艾什比的[必要多样性法则(Law of Requisite Variety)](艾什比定律_百度百科)——要实现控制,控制系统能够执行的行为的多样性,必须不低于需要应对的环境动荡的多样性
- 一个不断演化的分布式系统的复杂性,只会增加,而不会减少。依据是著有《人月神话》的那位大神Frederick Brooks的一篇文章中所谈到的两类复杂性(偶然复杂性与本质复杂性),都不会减少,甚至有一类还会增加。
其中,偶然复杂性,是在资源有限的条件下,对相互冲突的限制条件作出权衡后的必然结果。
不存在已知的可持续方法,能减少偶然复杂性,因为资源总是有限的,权衡总是要做出的,暗债总是要欠下的。
而本质复杂性,是满足不断增加的新需求的必然结果。一个不断演化的分布式系统,新需求能少得了吗?
混沌工程和测试有什么区别?
两者的运行环境有区别。
测试一般运行在**测试环境**上,而混沌猴一般运行在**生产环境**上。因为生产环境必然存在不可预知且与测试环境不同的暗债,所以对测试环境所建立的信心,并不能用在生产环境上。
两者的侧重点也有区别。
测试一般只关注**已知**的断言是否通过,而混沌工程会更关注发现更多**未知**的暗债。
混沌工程和故障演练啥区别?
两者的侧重点有区别。
故障演练侧重操练**已知**的故障应对过程,而混沌工程侧重通过实验发现**未知**的暗债。
生产环境是不允许引入任何风险的。如果混沌工程是在生产环境上做实验,那风险多大呀。领导会答应吗?
前面提到,暗债是生产系统这个复杂系统所固有且不可预知的。那么即使不人为地引入风险,生产环境也是遍布暗债的。不在生产环境进行最小化爆炸半径的实验,来发现暗债,那么**只能任凭暗债在最不希望发生的时刻爆发**。
该咋做混沌工程?
借鉴Netflix的实例,可以从“摆正心态、人员主动和试点业务”三方面入手,来启动混沌工程。
### 摆正心态
承认暗债为复杂系统所固有,而不是一味要求工程师[“不能也不该出现失误”](6月27日阿里云故障说明-阿里云开发者社区)。否则在故障面前,大家就只会花大量时间相互甩锅,耽误了发现更多暗债和防范措施。
### 人员主动
前面说过,根据必要多样性法则,要建立对系统能够承受生产环境的动荡的信心,需要针对生产环境“丰富多彩”的暗债,设计同样“丰富多彩”的防范手段。而技术骨干一个人,是发现不了那么多暗债,并找到那么多的防范手段的。所以,就需要发挥各位工程师的主动性。此时,领导者要创造能调动工程师主动性和创造性的企业文化,来促进工程师更安全地发现与修复更多“花样”的暗债。在修复暗债的过程中,就可以使用文章[【分布式系统稳定性设计入门】如果不想总是半夜爬起来抢修生产事故……《发布!》第2版解读](【分布式系统稳定性设计入门】如果不想总是半夜爬起来抢修生产事故……《发布!》第2版解读 v0.2)所介绍的“分布式系统稳定性设计关键清单”。
### 试点业务
- 选择一个出现生产事故频率较高的业务系统,尝试混沌工程。因为事故的反复,出现会让发现与解决暗债的动力更大
- 基于能反映用户体验的业务稳态行为建立假设,而不是先聚焦于在系统内寻找弱点。因为这样能更利于进行全局优化,让成效更大
- 为了让暗债浮现出来,设计引入足够多样化的现实世界可能发生的事件,而不是设计那些易于生成但在现实中不大可能出现的事件,以便切中要害。针对每一个所引入的事件,参考上述“分布式系统稳定性设计关键清单”,来进行稳定性设计
- 可以先从准生产环境入手进行混沌实验,等条件成熟后,再逐渐过渡到生产环境
- 自动化地持续进行混沌实验,以起到回归实验的效果,持续发现并解决暗债,避免系统随着时间的推移,在韧性方面逐渐“掉队”
- 设计更安全的实验方式,以最小化爆炸半径,让实验所导致的业务损失降到最低,而不是明知故障难以控制,还要贸然进行实验。如果实验的假设被证伪,那么就遇到了发现新的暗债的好机会。在寻找暗债的过程中,可以参考上述“分布式系统稳定性设计关键清单”,来启发寻找漏洞及修复
混沌工程的唯一目标就是证明系统存在缺陷。通过开展混沌工程方面的科学实验,你可以测试系统是否存在缺陷,从而了解系统在混乱的类生产环境条件下如何表现。
混沌工程属于一门新兴的技术学科,行业认知和实践积累比较少,大多数IT团队对它的理解还没有上升到一个领域概念。阿里电商域在2010年左右开始尝试故障注入测试的工作,希望解决微服务架构带来的强弱依赖问题。
参考来源1:https://zhuanlan.zhihu.com/p/149599011
参考来源2:https://zhuanlan.zhihu.com/p/149419512